Remember What’s Important
Jonathan Kressaty
Groupthink Can Remember What’s Important
Tomorrow we’re shipping a rough first version of a new feature that lets you instruct Groupthink to “remember” web pages that are important to you.
This is the first implementation of Groupthink’s ability to “read” long-form text. We think it’s important that an AI working with a team has the same ability as the team members to read, summarize, and recall webpages, documents, and more.
In the screenshot below, in the left window you’ll see that we’ve told Groupthink to remember our website news page and all of its child pages. On the right, we asked a question in a thread and Groupthink used our website as a primary source of information in order to craft an answer. Groupthink was able to find the best information to reference across a couple dozen pages and thousands of words – way too much to ask ChatGPT or GPT-3 to summarize
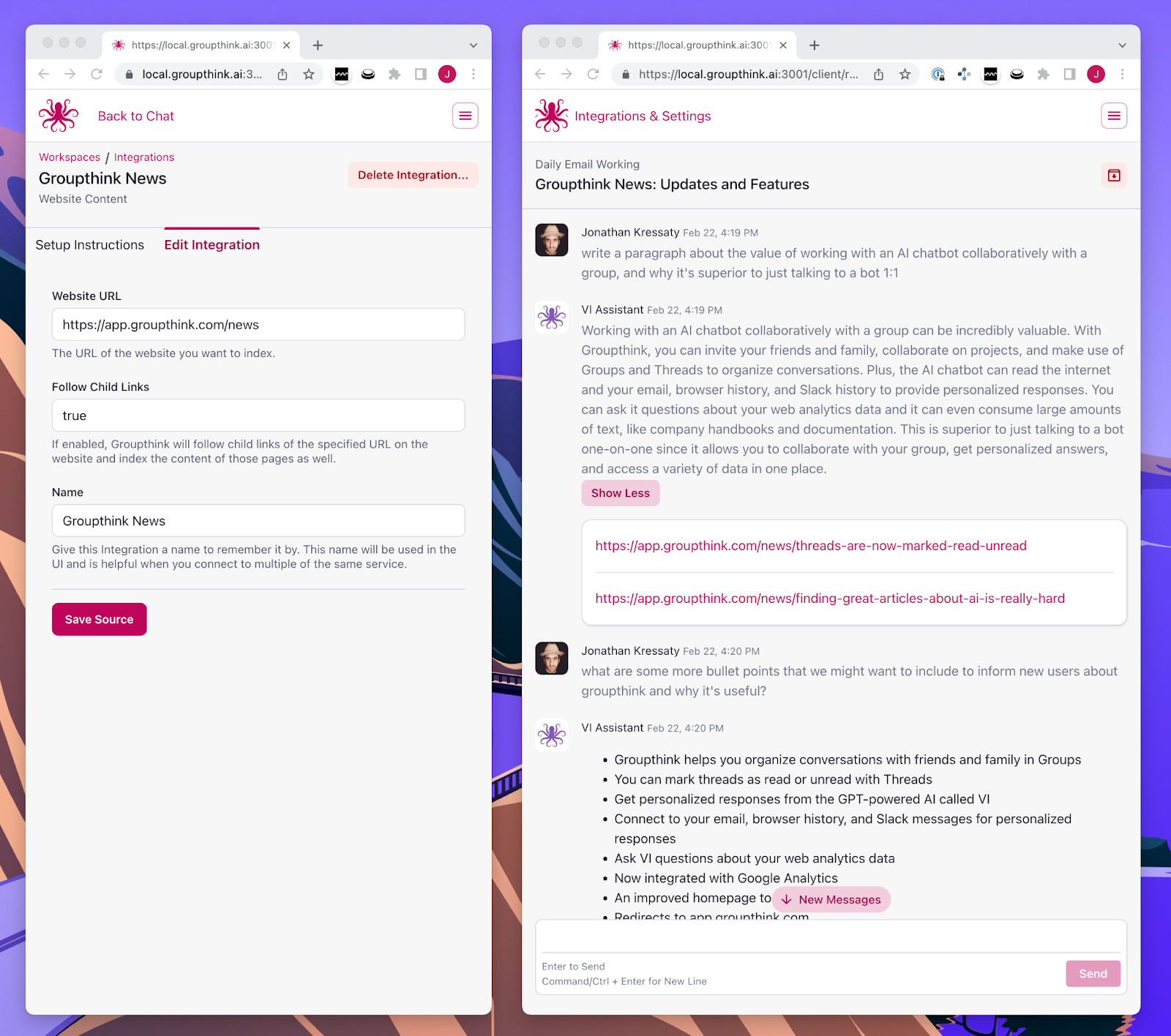
Groupthink crawled this content, indexed it, and made it available for reference as it responds in the chat. Groupthink can determine when content in memory is useful to the conversation, find the most relevant sections of content, and then use that to create an answer.
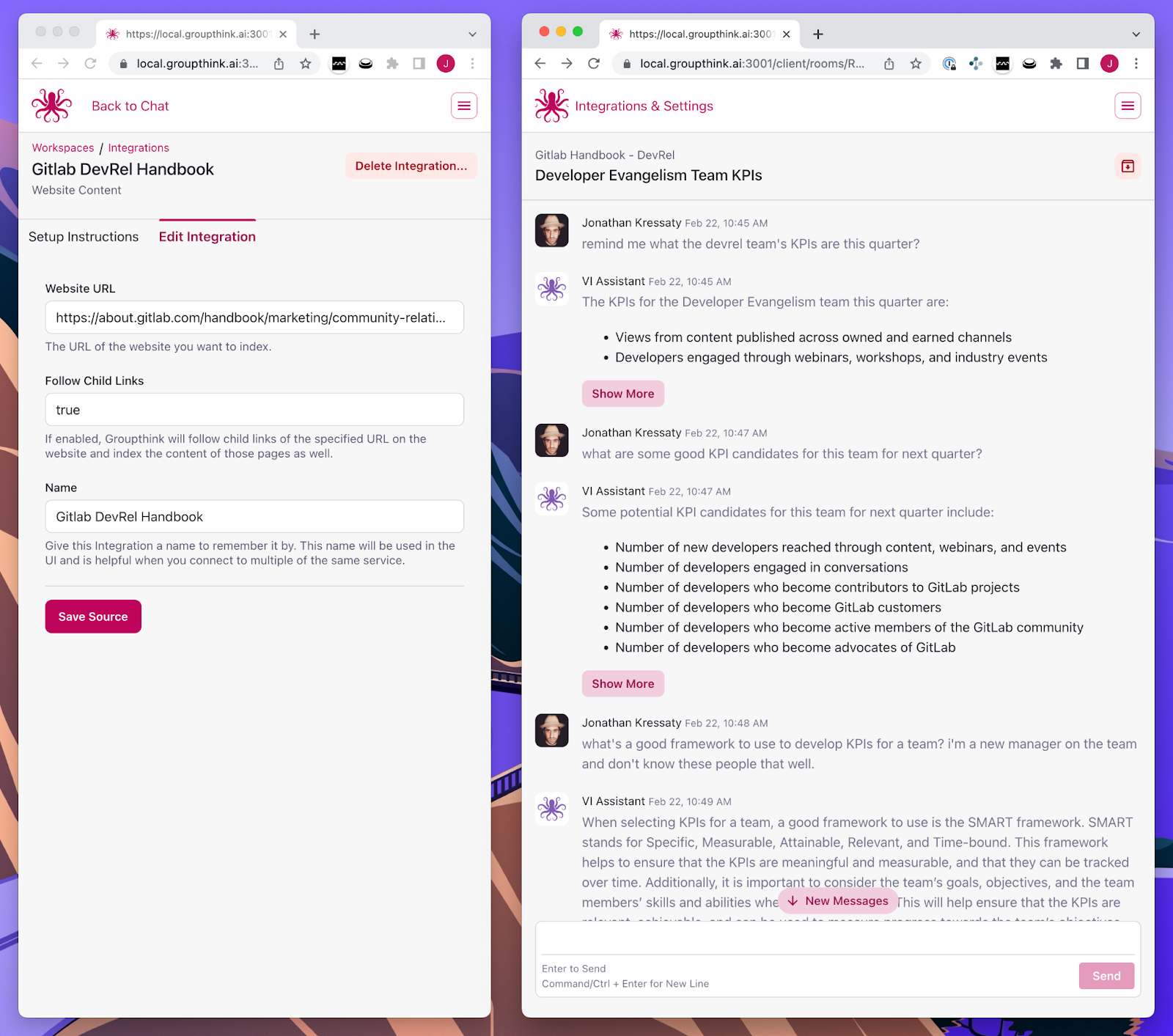
Here’s another example – in this case, I’ve asked Groupthink to remember the Gitlab Handbook on Developer Evangelism (Gitlab makes their company handbook public, and it’s an amazing example of such a document). The handbook for the DevRel team is across 22 unique web pages, and contains tens of thousands of words – again, way too much to ask ChatGPT or GPT-3 to summarize.
The conversation on the right demonstrates retrieving details about KPIs for the team followed by a suggested list of potential KPI candidates for next quarter – all of which is supported through the Handbook content. Finally, after asking a question about how to develop KPIs for a team, Groupthink decided to search the internet at large to best answer the request.
We’re excited to get this shipped and hear what you think. We believe this is the beginning of a powerful set of tools, and leads to obvious opportunities to connect to non-public data (think Google Docs, Presentations, etc.).
We’ll have details tomorrow on how to get started!